


SQL Corgs Explain Inner Joins
Joins are essential. The SQL Corgs introduce you to INNER joins in this animated short.
Joins are essential. The SQL Corgs introduce you to INNER joins in this animated short.
Why do we “normalize” relational databases, and what are the basics? Awkward Unicorn explains, with a little help from their friends.
Freyja the corgi shares her tips for learning SQL: SELECT, FROM, and WHERE.
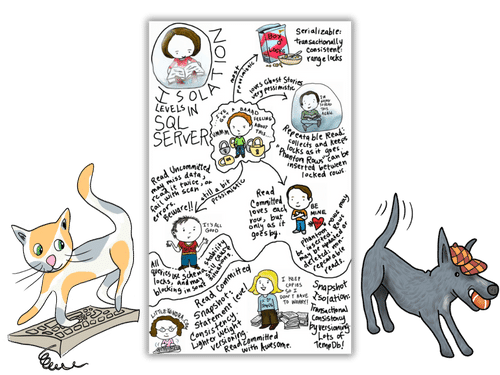
Now that I’m getting the hang of this, I think I’m going to do a whole series of shorts on SQL syntax essentials, plus tips and tricks!
I learned to make short form videos with my drawings this week, and, well… things are about to get weirder.
I’ve got a backlog of learnings from stress-testing to blog, so if you like this post there’s more to come. I’m a huge fan of SQL Server’s Query Store feature. Query Store collects query execution plans and aggregate query performance metrics, including wait stats. Having Query Store enabled makes troubleshooting performance issues such as bad parameter sniffing, much, much easier. Because Query Store is integrated into SQL Server itself, it also can catch query plans in a lightweight way that an external monitoring system will often miss.
I’ve been an employee at small, medium, and large companies, and I’ve also been a short-term consultant working with a new company in any given week. I’ve worked with hundreds of tech companies remotely and have visited companies onsite on multiple continents.
Air-dropping into company cultures to work through problems with teams and present recommendations to their leadership reveals common anti-patterns in leadership – plus some patterns that make teams raving fans of their management.
Here’s the top 5 Toxic Flavors of Tech Execs I’ve encountered over 20 years, plus the Top 5 Team Building Tech Execs I’ve found, too.
Back in my 20’s, I was lucky enough to go to graduate school. I had a work-study job in the Dean’s office where I got to develop and administer their Access databases, which helped me get by. One day, the Dean said to me: “Kendra, when you talk about your work on our databases, you light up. When you talk about your coursework, that doesn’t happen. Have you thought about that?
Last November, a puzzle was really bothering me. Some queries from an application were timing out frequently after running for 30 seconds, but they were halfway invisible in the SQL Server.
Copyright (c) 2024, Catalyze SQL, LLC; all rights reserved. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.






