on December 23, 2010
Imagine that you are writing a script that looks at data grouped by the minute. You notice that there are no rows for some minutes, and you’d like to display a value when that is the case, probably showing a count of zero.
In thinking about this problem this week, I spent some time getting to know CTEs (Common Table Expressions) again. And I came to the conclusion that I should spend much more time with them. Maybe I won’t end up using them all the time, but I should be looking at them regularly as options when I’m writing queries.
Here’s the story of a handy way I found to work with this.
Let’s create some data
Our story starts with some data. It’s been lovingly scripted out, but it has a few holes.
CREATE TABLE dbo.MyImperfectData (
ItemDate DATETIME2(0) ,
ItemCount SMALLINT );
GO
INSERT dbo.MyImperfectData ( ItemDate, ItemCount )
VALUES ( '2010-12-01 00:00:00', 12 ),
( '2010-12-01 00:01:00', 3 ),
( '2010-12-01 00:02:00', 6 ),
( '2010-12-01 00:03:00', 12 ),
( '2010-12-01 00:04:00', 24 ),
( '2010-12-01 00:05:00', 1 ),
-- Gap where 6 would be
( '2010-12-01 00:07:00', 122 ),
( '2010-12-01 00:08:00', 1 ),
( '2010-12-01 00:09:00', 1244 ),
( '2010-12-01 00:10:00', 23 ),
( '2010-12-01 00:11:00', 12 ),
( '2010-12-01 00:12:00', 24 ),
( '2010-12-01 00:13:00', 27 ),
( '2010-12-01 00:14:00', 28 ),
--Gap where 15, 16, 17 would be
( '2010-12-01 00:18:00', 34 ),
( '2010-12-01 00:19:00', 93 ),
( '2010-12-01 00:20:00', 33 ),
( '2010-12-01 00:21:00', 65 ),
( '2010-12-01 00:22:00', 7 ),
( '2010-12-01 00:23:00', 5 ),
--Gap where 24 would be
( '2010-12-01 00:25:00', 4 ),
( '2010-12-01 00:26:00', 6 ),
( '2010-12-01 00:27:00', 7 ),
( '2010-12-01 00:28:00', 77 ),
( '2010-12-01 00:29:00', 94 );
GO
CREATE UNIQUE CLUSTERED INDEX cxMyCTE ON dbo.MyImperfectData(ItemDate);
GO
The data is at the minute level. We’re missing data for five minutes in this period– one three minute chunk, and two other minutes.
What’s the quickest way to show the missing rows?
At first I thought about querying the data itself to find what’s missing. This made my head hurt a bit, and seemed pretty expensive.
I thought about the fact that many data warehouse databases have calendar tables, where all sorts of information about months, days, years, hours, and minutes are normalized out into tables.
However, I didn’t have those types of tables around. For the scope of my problem I was dealing with short date ranges (and by short, I mean 3 hours) , and ideally I would not need to create a bunch of ancillary objects to fill in the gaps.
After some thinking, I realized that we can create a date time table at the minute level on the fly by using a recursive CTE.
Here’s a sample that counts out a few minutes:
WITH MyCTE
AS ( SELECT CAST('2010-12-01 00:00:00' AS DATETIME2(0)) AS [I can count!]
UNION ALL
SELECT DATEADD(mi, 1, [I can count!])
FROM MyCTE
WHERE [I can count!] < DATEADD(mi, -1,
CAST('2010-12-01 00:10:00' AS DATETIME2(0))) )
SELECT [I can count!]
FROM MyCTE
OPTION ( MAXRECURSION 0 ) ;
Our results:
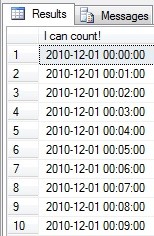
Putting it all together
Taking the format of this CTE, we can change it to create a table with every minute in our time range.
We can then select from it and use a LEFT OUTER JOIN to our table with data, and use the CTE dates to fill in the gaps.
DECLARE @startDate DATETIME2(0) , @endDate DATETIME2(0) ;
SELECT @startdate = MIN(ItemDate), @endDate = MAX(ItemDate) FROM dbo.MyImperfectData ;
WITH MyCTE AS
( SELECT
@startDate AS MyCTEDate
UNION ALL
SELECT
DATEADD(mi, 1, MyCTEDate)
FROM MyCTE
WHERE MyCTEDate < DATEADD(mi, -1, @endDate)
)
SELECT
MyCTEDate,
CASE WHEN Itemcount IS NULL THEN '[Missing Row]' ELSE '' END AS ColumnDescription,
COALESCE(ItemCount, 0) AS ItemCount
FROM MyCTE
LEFT OUTER JOIN dbo.MyImperfectData ld ON MyCTE.MyCTEDate = ld.ItemDate
ORDER BY MyCTEDate
OPTION ( MAXRECURSION 0 ) ;
GO
And there we have it! No gaps:
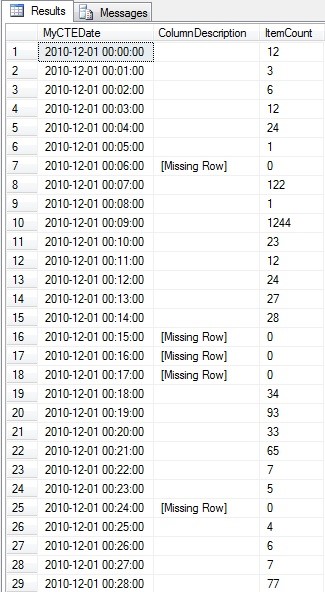
Follow up– this doesn’t scale well
In my initial posting, I didn’t say enough about where this is best applied, and how this scales.
I think this is mostly a party trick, but it’s also a nice simple example of recursion that got me thinking about CTEs. And while there are some situations where it can come in useful, it doesn’t scale up to large date ranges. (Check out Brad Schulz' post on recursive CTEs here.)
So in other words, this may be helpful in some ad-hoc situations.
However, looking at the “pseudo-recursive” parts of Brad’s post, I really feel a follow-up post or two coming on.