on February 25, 2016
Trainers and speakers need the code they write to be predictable, re-runnable, and as fast as possible. Faking writes can be useful for speakers and teachers who want to be able to generate some statistics in SQL Server’s index dynamic management views or get some query execution plans into cache. The “faking” bit makes the code re-runnable, and usually a bit faster. For writes, it also reduces the risk of filling up your transaction log.
I didn’t invent either of the techniques used below. Both patterns are very common and generic, and so simple that no origin is known.

Lots of Tiny Writes: The ROLLBACK Trick
SQL Server counts inserts, updates, or deletes as happening even if it was rolled back. This seems kind of weird at first, but I think it actually makes sense. And hey, rollback is often slow and painful enough that why add on the overhead of updating the DMVs again?
So if I want to simulate 6017 writes to this table in the SQLIndexWorkbook database (now renamed to BabbyNames), I can use code like this:
SET NOCOUNT ON;
GO
USE SQLIndexWorkbook
GO
BEGIN TRAN
INSERT INTO agg.FirstNameByYear (ReportYear, FirstNameId, Gender, NameCount)
VALUES (2001,1,'F',100)
ROLLBACK
GO 6017
As long as my line of code doesn’t generate a unique or PK violation, this code is fully rerunnable. Sure, the GO # is trashy, but it’s much easier to read and maintain than writing a loop. Plus, I don’t actually want to increase the table size every time I want to increment the write counter.
Here’s the code to verify those writes were really recorded in the index DMVs:
SELECT
ix.name,
ius.user_updates,
ius.user_scans,
ius.user_seeks
FROM sys.dm_db_index_usage_stats ius
JOIN sys.indexes ix on ius.object_id=ix.object_id and ius.index_id=ix.index_id
JOIN sys.objects so on ix.object_id=so.object_id
JOIN sys.schemas sc on so.schema_id=sc.schema_id
WHERE
ius.database_id=DB_ID()
and sc.name='agg'
and so.name='FirstNameByYear'
GO
Viola! Writes were recorded for my Clustered PK as well as both nonclustered indexes:
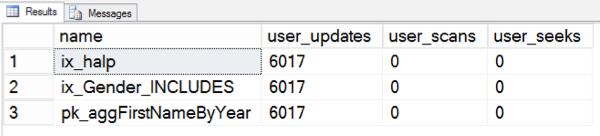
Inserts, updates, and deletes are all categorized by SQL Server as “user updates”. Because reasons.
Warning - ROLLBACK Trick is Not Suitable for Large Transactions
This rollback trick will not make updating a large table any faster. It doesn’t look at the block of code and see the rollback and know just to not execute it! And rollback is always single threaded. This trick is really only helpful for mimicking a ton of small operations without having to write loops or actually have your tables grow.
Secret 2: Dump Return Values into Variables Instead of Returning them to the Client
To fake out SQL Server on the reads, the main thing to avoid is the overhead of returning result sets to your client. It’s wasted effort that slows you down. And I’m not the only one who’s enjoyed out of memory errors in SQL Server Management Studio, I’m guessing. This avoids that.
The trick is in the “@garbage”:
DECLARE @garbage INT
SELECT
@garbage = NameCount
FROM agg.FirstNameByYear
WHERE
Gender='F'
and FirstNameId = 210;
GO 2144
I prefer this to setting “discard results” on the session because:
- It’s not manual and I don’t have to remember to do it every single time. Or get confused every time I forget to reverse the setting.
- “Discard results” also discards errors in the Messages tab, and I do want to see those in case I’ve missed something important– like setting the database context properly.
Using the same code above, I can see that my query did a seek against one of my indexes:
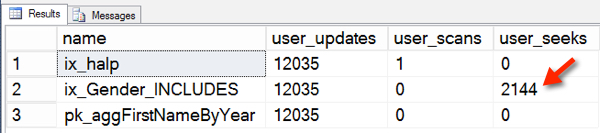 ]
]
I did more writes between screenshots. It wasn’t gremlins.
Always Test Demo Setup to Make Sure It’s Rerunnable!
The primary cause of demo failure is not having a setup script that fully resets everything properly. I always do multiple iterations of running my setup script and then testing demos to make sure they behave as expected – it takes some time, but helps avoid some sweaty moments in the classroom.
 REGISTER
REGISTER